
In der Welt der Datenwissenschaft und des maschinellen Lernens gehören Generative Adversarial Networks (GANs, auf deutsch: erzeugende generische Netzwerke) zu den spannendsten neuen Entwicklungen. In einem GAN treten zwei verschiedene Netze in einem Nullsummenspiel gegeneinander an, um realistische Bilder oder andere Daten zu erzeugen. Die zunehmende Beliebtheit von GANs ist auf ihre Fähigkeit zurückzuführen, mit wenigen Trainingsdaten hochwertige Ergebnisse zu erzielen.
GANs sind eine Art neuronales Netz, das für die generative Modellierung verwendet wird. Generative Modellierung ist ein Teilbereich des maschinellen Lernens. Hier besteht das das Ziel darin, neue Beispiele zu erzeugen, die den Trainingsdaten ähnlich sind. Ein GAN, das auf Bildern von Gesichtern trainiert wurde, kann beispielsweise dazu verwendet werden, neue Gesichter zu generieren. Die neuen Bilder sehen zwar realistisch aus, bilden aber keine reale Person ab.
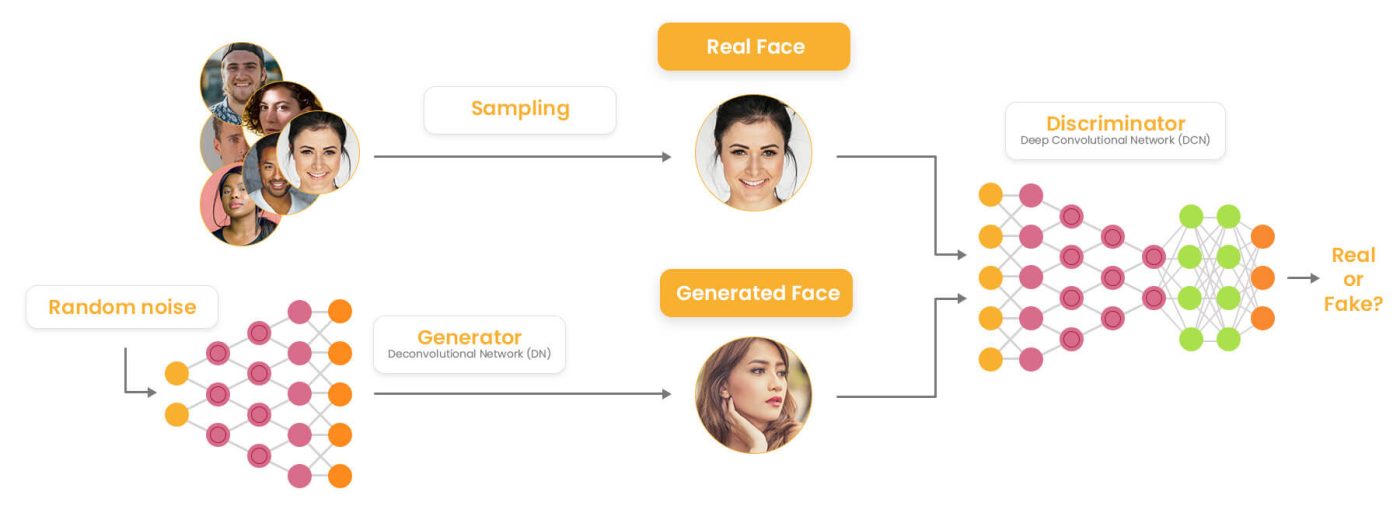
GANs setzen sich aus zwei Teilen zusammen: einem Generator und einem Diskriminator.
Beide Netze werden gemeinsam in einem kontradiktorischen Prozess trainiert: Der Generator versucht, den Diskriminator zu täuschen, während der Diskriminator lernt, gefälschte Beispiele zu erkennen.
Mit fortschreitendem Training erzeugt der Generator zunehmend realistischer wirkende Beispiele. Der Diskriminator dagegen wird immer besser darin, diese zu erkennen. Das Endergebnis ist ein Modell, das neue, überzeugend echt wirkende Beispiele erzeugt.
GANs funktionieren, indem zwei neuronale Netze gegeneinander trainiert werden. Das Generator-Netzwerk erzeugt gefälschte Daten, und das Diskriminator-Netzwerk versucht zu gefälschte Daten als solche zu identifizieren. Durch das Training werden beide Netzwerke optimiert.
Das Endergebnis ist ein Satz von generierten Daten, der sehr realistisch ist. GANs werden zur Generierung von Bildern, Videos und Text verwendet. Sie haben eine breite Palette von Anwendungen in Bereichen wie Computer Vision, Verarbeitung natürlicher Sprache und generative Modellierung.
Einführung in GAN – by Serrano.Academy
GANs werden für eine Vielzahl von Aufgaben eingesetzt, darunter die Erzeugung neuer Bilder, Videos und Texte. Auch andere praktische Anwendungen sind möglich. Beispiele:
GANs sind ein relativ neues Forschungsgebiet. Die wachsende Verbreitung von GANs wird wahrscheinlich viele neue und kreative Anwendungen möglich machen.
Der Hauptvorteil von GANS besteht darin, dass sie künstliche Daten erzeugen, die den realen Daten sehr ähnlich sind. Das liegt daran, dass GANs aus zwei neuronalen Netzen bestehen. Generator und Diskriminator konkurrieren miteinander. Dadurch wird der Generator immer besser darin, realistische Daten zu erzeugen. Dies macht GANs zu einem unschätzbaren Werkzeug für die Datenerweiterung oder für die Erstellung von Trainingsdaten für maschinelle Lernmodelle.
GANs werden in der Regel für Bilderzeugungsaufgaben eingesetzt, können aber auch für andere Datentypen wie Text oder Audio verwendet werden.
Die Verwendung von GANs zur Datengenerierung hat mehrere Vorteile:
Insgesamt sind GANs ein leistungsstarkes Werkzeug für künstliche Intelligenz und maschinelles Lernen. Sie können für eine Vielzahl von Aufgaben eingesetzt werden und bieten mehrere Vorteile gegenüber anderen Arten von generativen Modellen.
Tipp:
Möchten auch Sie mit dem Einsatz von GANs hochwertige Ergebnisse erzielen? Holen Sie sich passende Trainingsdaten in Form von Fotos, Video- oder Audioaufnahmen. Ganz nach Ihren Wünschen von clickworker.
Mehr über KI-Trainingsdaten
GANs können hochwertige Daten erzeugen. Aber es gibt auch einige Nachteile bei der Verwendung dieser Technologie.
GANs haben sich in den letzten Jahren als ein leistungsfähiges Werkzeug erwiesen, das realistische Daten aller Art erzeugen kann. Es gibt aber immer noch offene Fragen darüber, wie GANs funktionieren und wie sie am besten trainiert und optimiert werden können. Die aktuelle GAN-Forschung hat drei Hauptrichtungen:
Indem wir uns mit diesen Fragen befassen, können wir das Potenzial von GANs weiter optimieren und deren Leistungsfähigkeit zur Generierung realistischer Daten noch besser nutzen.
Beim maschinellen Lernen sind generative Modelle eine Art von Algorithmus, mit dem die zugrunde liegende Verteilung eines Datensatzes erlernt wird. Dadurch können sie neue Daten erzeugen, die den ursprünglichen Daten ähnlich sind. Generative kontradiktorische Netze sind eine Art neuronales Netz, das zwei Modelle verwendet: einen Generator und einen Diskriminator.
Der Generator erzeugt neue Daten, während der Diskriminator versucht, die Daten entweder als echt oder als gefälscht zu klassifizieren. Die beiden Modelle werden gemeinsam trainiert. Das Ziel ist, dass der Generator Daten erzeugt, die von den echten Daten nicht zu unterscheiden sind. GANs wurden bereits zur Erzeugung realistischer Bilder, Videos und Texte eingesetzt. Sie werden auch immer beliebter für Anwendungen wie Bildbearbeitung und Stilübertragung.
Der Hauptunterschied zwischen überwachtem und unüberwachtem Lernen bei GANs ist die Art des Feedbacks, das der Generator während des Trainings erhält.
Welcher Ansatz letztlich besser ist, hängt von den spezifischen Zielen des Trainingsprozesses ab.
Im Bereich des maschinellen Lernens gibt es zwei Haupttypen von Modellen zur Datengenerierung: diskriminative und generative Modelle.
In den letzten Jahren haben sich GANs zu einer beliebten Technik für das Training generativer Modelle entwickelt. Das Generatornetz lernt, gefälschte Datenpunkte zu erzeugen, die realistisch genug sind, um das Diskriminatornetz zu täuschen. Es lernt, zwischen echten und gefälschten Datenpunkten zu unterscheiden. Dieser Wettbewerb zwischen den beiden Netzen führt dazu, dass das Generatornetz seine Fähigkeit, realistische Datenpunkte zu erzeugen, allmählich verbessert.
In einem GAN arbeiten das Generatornetz und das Diskriminatornetz. Der Generator ist für die Erzeugung neuer Daten beziehungsweise Informationen zuständig. Das Diskriminatornetz versucht, zwischen echten Daten und gefälschten Daten zu unterscheiden.
Damit ein GAN funktionieren kann, müssen beide Netze gleichzeitig trainiert werden. Im Allgemeinen wird das Generatornetz zunächst Daten von geringer Qualität erzeugen, aber im Laufe des Trainings lernt es allmählich, realistischere Daten zu erzeugen. Das Diskriminatornetz dagegen kann zu Beginn leicht zwischen echten und gefälschten Daten zu unterscheiden.
Mit zunehmendem Training wird es jedoch immer besser, gefälschte Daten zu erkennen, bis es schließlich nicht mehr zwischen echten und gefälschten Daten unterscheiden kann.
GANs sind eine Art von neuronaler Netzarchitektur, die für die generative Modellierung verwendet wird. Die Grundidee besteht darin, zwei Netze zu haben, einen Generator und einen Diskriminator, die in einem spieltheoretischen Rahmen miteinander konkurrieren. Der Generator versucht, Daten zu erzeugen, die realistisch genug sind, um zu täuschen.
Das Generatormodell ist der Teil der GAN-Architektur, der für die Datenerzeugung zuständig ist.
Das Generatormodell wird durch das Feedback des Diskriminatormodells trainiert. Wenn es den Diskriminator erfolgreich täuscht, erhält es eine positive Belohnung, wenn es versagt, eine negative Belohnung.
Es gibt viele verschiedene Arten von Generatormodellen, die vorgeschlagen wurden, aber sie haben alle das gleiche grundlegende Ziel: einen niedrigdimensionalen Rauschvektor in einen hochdimensionalen Datenvektor zu transformieren, der realistisch genug ist, um den Diskriminator zu täuschen.
Zu den gängigen Typen von Generatormodellen gehören vollständig verbundene Netze, Faltungsnetze und rekurrente Netze. Jeder Typ hat seine eigenen Vor- und Nachteile. Deshalb gibt es keinen idealen Weg zur Entwicklung eines Generatormodells. Letztendlich hängt die Wahl der Architektur von der jeweiligen Anwendung ab.
Das Diskriminatornetz wird ebenfalls mit echten Daten trainiert, so dass es immer besser darin wird, gefälschte Daten zu erkennen. Das Ziel des Generatornetzes ist es, Daten zu erzeugen, die so realistisch sind, dass das Diskriminatornetz sie nicht von den echten Daten unterscheiden kann.
Das Ergebnis ist ein Modell, das realistische Datenproben erzeugen kann. Das Diskriminatormodell spielt in GANs eine wichtige Rolle, da es dem Generatornetzwerk Feedback gibt.
Ohne diese Rückkopplung hätte das Generatornetz keine Möglichkeit zu erkennen, ob seine synthetischen Daten realistisch sind oder nicht. Je mehr Daten in das System eingespeist werden, desto besser kann das Diskriminator-Netzwerk gefälschte Daten erkennen, was wiederum die Qualität der vom Generator-Netzwerk erzeugten synthetischen Daten verbessert.
Convolutional Neural Networks (faltende neuronale Netze
) sind eine Art Deep-Learning-Algorithmus, der sich besonders gut für Bildklassifizierungsaufgaben eignet. Andererseits sind GANs eine Art von Algorithmus, der zur Erzeugung neuer Datenmuster auf der Grundlage eines Trainingssatzes verwendet wird. In jüngster Zeit hat die Verwendung von GANs zur Erzeugung realistischer Bilder großes Interesse geweckt, und es wurden bereits zahlreiche Spitzenergebnisse erzielt.
Das Training von GANs kann jedoch schwierig sein, und es ist oft notwendig, Convolutional Neural Networks als Teil des Trainingsprozesses zu verwenden. Darüber hinaus können diese faltungsneuronalen Netze
zur Verbesserung der Ergebnisse von GANs verwendet werden, indem sie zusätzliche Beschränkungen bereitstellen. Folglich ist die Kombination von Convolutional Neural Networks und GANs ein leistungsfähiges Werkzeug für Bilderzeugungsaufgaben.
Einfache Architektur eines GAN
Ein bedingtes GAN (Conditional GAN, cGAN) ist eine Art von generativem adversarischem Netzwerk (GAN), bei dem der Generator lernt, Bilder unter bestimmten Bedingungen zu erzeugen. Ein cGAN könnte zum Beispiel darauf trainiert werden, Bilder von Gesichtern zu erzeugen, die digital so verändert wurden, dass sie wie eine bestimmte Person aussehen.
cGANs werden auch für die Text-Bild-Synthese, die 3D-Objektrekonstruktion und die Super-Resolution verwendet.
Im Gegensatz zu anderen KI-Algorithmen, die sich auf bereits vorhandene Datensätze stützen, erzeugen GANs eigene Daten, indem sie neuronale Netze gegeneinander trainieren.
GANs wurden bereits eingesetzt, um realistische Bilder von Gesichtern, Tieren und sogar Autos zu erzeugen. Da sich die Technologie weiter entwickelt, ist es wahrscheinlich, dass GANs einen immer größeren Einfluss auf die KI-Welt haben werden.
Beim Training eines GAN sind einige wichtige Aspekte zu beachten:
Wenn Sie diese Tipps befolgen, können Sie sicherstellen, dass Ihre GAN ihr volles Potenzial entfalten kann.
GANs haben viele potenzielle Anwendungen. Das sind zum Beispiel die Erstellung neuer Kunstwerke oder die Erzeugung synthetischer Daten für das Training von Modellen des maschinellen Lernens. Darüber hinaus könnten GANs verwendet werden, um realistische Datenmuster zu erzeugen, die sonst nur schwer zu beschaffen sind, wie zum Beispiel medizinische Bilder.
Letztendlich werden die möglichen Anwendungen von GANs nur durch die Vorstellungskraft der Entwickler begrenzt, die mit ihnen arbeiten.
Obwohl sich Generative Adversarial Networks noch in einem frühen Entwicklungsstadium befinden, zeigen sie bereits ein großes Potenzial für die Zukunft der Datengenerierung und Datenanalyse. Die Fähigkeit, realistische Datensätze zu generieren, hat viele potenzielle Anwendungen in Bereichen wie dem Gesundheitswesen, dem Finanzwesen und der Produktion. Bei fortgesetzter Entwicklung könnten GANs bald unverzichtbar werden – für Forscher wie für Unternehmen.

