
Die Digitalisierung bringt in einem rasanten Tempo neue Technologien hervor, die unser Leben einfacher machen. Unternehmen nutzen Tools und Technologien, um ihre Prozesse zu rationalisieren. Dabei spielen Künstliche Intelligenz (KI) und Maschinelles Lernen (ML) eine immer wichtigere Rolle. Denn KI und ML schaffen deutliche Wettbewerbsvorteile.
Maschinelles Lernen ist heute ein unverzichtbares Element im Business. Die Leistung von KI- und ML-Modellen hängt aber von der Qualität der Daten ab, mit der diese Systeme arbeiten. Deshalb zeigen wir hier, wie wichtig es ist, geeignete Datensätze für das maschinelle Lernen zu sammeln und die besten Methoden für das Sammeln zu verwenden.
In den meisten Fällen verfügen Daten bereits über hochwertige Bezeichnungen. Wenn Sie zum Beispiel die Aktienkurse aus den vorherigen Werten projizieren, dient der Preis sowohl als Eingangsmerkmal als auch als Zielbezeichnung.
Dies ist jedoch nicht immer der Fall. Denn viele Datenkennzeichnungen haben keine hohe Qualität. Einige Beschriftungen, wie beispielsweise vom Benutzer hinzugefügte Tags und Kategorien, sind voreingenommen oder zumindest subjektiv. In anderen Fällen haben die Daten möglicherweise gar keine Kennzeichnungen, wie zum Beispiel bei der Objekterkennung.
Hier kommt die Datenkommentierung ins Spiel, denn sie hilft Ihnen bei der Erfassung von Kennzeichnungen und der Verbesserung ihrer Qualität.
Bei der Datenannotation werden die Daten mithilfe von Annotationswerkzeugen und Algorithmen beschriftet oder neu beschriftet. Dies hilft zum Beispiel bei
Was sind also von Menschen kommentierte Daten? Warum sind sie so wichtig? Und was sind die Vorteile ihrer Verwendung? In diesem Artikel werden wir diese und andere Fragen besprechen, um Ihnen eine umfassende Vorstellung von der Datenkommentierung zu vermitteln.
Die meisten Daten, die heute zur Verfügung stehen, sind unstrukturiert – also nicht korrekt definiert. Beim Aufbau eines KI-Modells müssen die richtigen Informationen in den Algorithmus eingespeist werden, damit dieser die gewünschten Ergebnisse liefern kann.
Dieser Prozess kann nur stattfinden, wenn der Algorithmus die von Ihnen eingegebenen Daten versteht. Erst dann kann der Algorithmus die Daten entsprechend klassifizieren.
Datenannotation bezeichnet den Prozess, Daten in eine für ML-Algorithmen leicht verständliche Form zu bringen. Es geht darum, Daten entsprechend zuzuordnen, zu markieren oder zu beschriften, damit die ML- und KI-Projekte sie verstehen können.
Kurz gesagt: Datenbeschriftung und Datenanmerkung bedeutet, die entsprechenden Details oder Informationen im Datensatz zu markieren. Auf diese Weise können Maschinen den Datensatz verstehen und entsprechend nutzen. Die Daten selbst können in jeder Form vorliegen, zum Beispiel als Bilder, Videos, Audio oder Text.
Die Kennzeichnung von Komponenten in Daten ermöglicht es den ML-Modellen, die zu verarbeitenden Informationen genau zu erfassen. Die Modelle speichern auch frühere Informationen, um neue Details auf der Grundlage des vorhandenen Wissens automatisch zu verarbeiten und rechtzeitig Entscheidungen zu treffen.
Neben dem Verständnis der Daten hilft der Prozess der Datenkommentierung den KI- und ML-Modellen auch zu erkennen, ob es sich bei dem empfangenen Datensatz um ein Bild, Audio, Video, Text oder eine Kombination von Formaten handelt. Als Nächstes klassifiziert das Modell die Daten und führt die Aufgaben entsprechend den von Ihnen zugewiesenen Merkmalen und Parametern aus.
Datenkommentare sind wichtig. Denn KI- und ML-Modelle müssen konsequent trainiert werden, um ständig effektivere Ergebnisse zu erzielen. Dieser Prozess ist beim überwachten Lernen von entscheidender Bedeutung: Je mehr kommentierte Daten Sie dem Modell zuführen, desto schneller wird es beginnen, sich selbst zu trainieren – ohne Hilfe.
Nehmen wir als Beispiel ein selbstfahrendes Auto, das sich auf Daten aus verschiedenen technischen Elementen stützt, zum Beispiel:
Die Algorithmen in diesen technischen Elementen verwenden Datenkommentare, damit das Fahrzeug an jedem Punkt präzise Fahrentscheidungen treffen kann. Ohne Datenkommentare können die KI- und ML-Modelle nicht erkennen, ob das sich nähernde Hindernis eine Person, ein Tier oder ein anderes Fahrzeug ist.
Daher würden die Ergebnisse des KI-Modells ohne Datenkommentar ungünstige Ergebnisse liefern. Die Implementierung der Datenkommentierung ermöglicht es Ihnen, Ihre KI-Modelle präzise zu trainieren. Als Ergebnis erhalten Sie ein vollständiges Modell, das Ihnen die gewünschten Ergebnisse liefert – unabhängig davon, ob Sie das Modell für die Spracherkennung, für Chatbots oder einen anderen Prozess einsetzen.
Tipp:
Rohe KI-Trainingsdatensätze sowie von Menschen kommentierte Daten (zum Beispiel Bilder) können Sie einfach und schnell über Clickworker beziehen.
Mehr über Bildbeschriftungsdienste
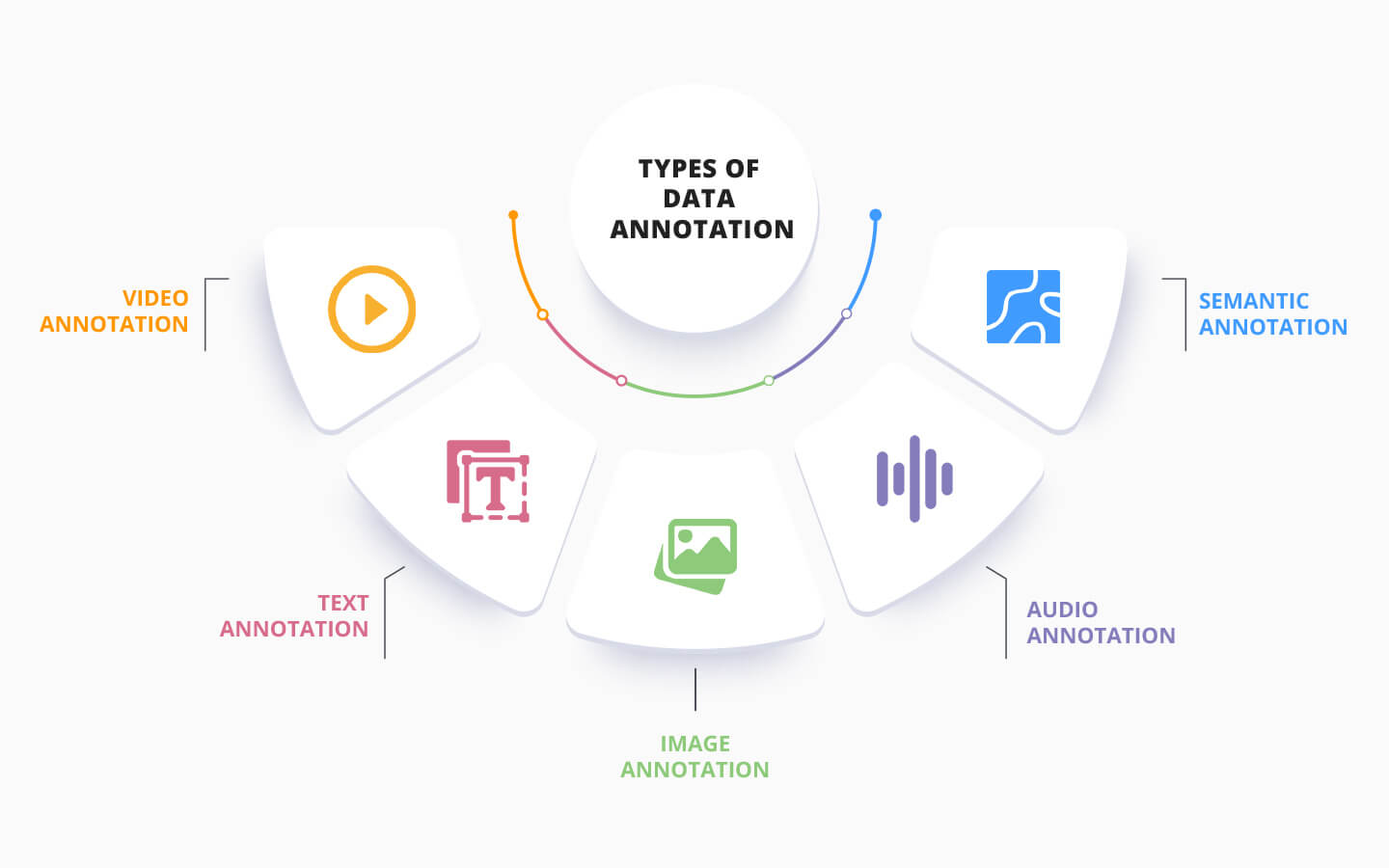
Es gibt verschiedene Arten von Datenanmerkungen. Für jeden Datentyp gibt es ein eigenes Beschriftungsverfahren. Im Folgenden finden Sie einige Beispiele für die gängigsten Arten von Datenkommentaren.
Bei der Videoanmerkung werden Methoden wie Bounding Boxes verwendet, um die Bewegung Bild für Bild zu ermitteln. So erhalten Sie Daten, die für KI- und ML-Modelle zur Objektlokalisierung und Objektverfolgung unerlässlich sind. Die Videoanmerkung ermöglicht die einfache Implementierung verschiedener Konzepte wie die Suche nach Objekten oder Bewegungsunschärfe in den Systemen.
Textanmerkung ist eine Technik, bei der Text in einem bestimmten Dokument je nach Thema und Kontext in verschiedene Kategorien eingeordnet wird: von einer Erwähnung in den sozialen Medien bis hin zu Kundenrezensionen über ein Produkt. Die Themen sind unerschöpflich.
Texte vermitteln eine klare und bessere Vorstellung von den Absichten, die dahinter stehen. Es ist einfach, durch Textannotation praktische und wertvolle Informationen daraus zu gewinnen. Sie sollten allerdings beachten, dass der Prozess der Textannotation oft komplex ist. Er umfasst verschiedene Phasen, da die ML-Modelle keine Konzepte und Emotionen kennen.
Die Bildbeschriftung ermöglicht es ML-Modellen, den beschrifteten Bereich als eigenständiges Element zu erkennen. Zum Training von Modellen werden Beschriftungen, Alt-Texte und Schlüsselwörter verwendet, um die Bilder zu beschreiben.
Auf diese Weise kann der Algorithmus die Bilder leichter verstehen und zuordnen. Bei der Annotation von Bildern werden in der Regel KI-basierte Anwendungen für Bounding Boxes und semantische Segmentierung eingesetzt.
Bei der Audiobeschriftung müssen verschiedene Parameter im Audiomaterial identifiziert werden. Dies geschieht mithilfe von Tagging. Hier kommen verschiedene Techniken zum Einsatz:
Neben verbalen Hinweisen können Sie auch Instanzen wie Stille und Weite anmerken.
Die semantische Annotation bezieht sich auf das Hinzufügen von Tags zu verschiedenen Konzepten wie beispielsweise Personen, Organisationsnamen und Orten in einem Dokument. Dies unterstützt ML-Modelle bei der Einteilung von neuen Konzepten für Texte in geeignete Kategorien.
Diese Annotation ist für KI- und ML-Training wichtig, um die Fähigkeiten von Chabots zu verbessern und die Suchrelevanz zu erhöhen. Die semantische Annotation umfasst in der Regel die Kennzeichnung von Schlüsselwörtern und den richtigen Identifikationsparameter.
Computer liefern schnelle und präzise Ergebnisse. Wie kann Maschinelles Lernen diese Fähigkeiten entwickeln und effiziente Ergebnisse liefern?
Die Antwort auf diese Frage ist Datenkommentierung. In der Entwicklungsphase nehmen ML-Module große Mengen von KI-Trainingsdaten auf. Dies hilft ihnen dabei, bessere Entscheidungen zu treffen und die Objekte oder Elemente zu entdecken.
Ohne Datenannotation ist jedes Bild für ein KI-System gleich. Es hätte keine Informationen über das Objekt und könnte es daher nicht verstehen. Deshalb ist die Datenkommentierung ein notwendiges Element für für folgende Aufgaben:
Jedes Modell, das von ML- oder KI-Funktionen angetrieben wird, nutzt Datenkommentierungsprozesse, um sicherzustellen, dass seine Entscheidungen genau und relevant sind.

Ein weiterer wichtiger Aspekt bei der Kennzeichnung und Kommentierung von Daten ist die Beteiligung von Menschen: Human Annotated Data. Solche Daten haben eine besondere Qualität. Denn Menschen können Dinge lernen, erkennen und verstehen, die ML-Modelle selbst nicht begreifen können. Beispiele:
Zusätzlich zu diesen Punkten ist die Einhaltung bestimmter Vorschriften oder Schritte in einem ML-Workflow nur durch menschliche Hilfe möglich. Die Notwendigkeit von Hilfe durch menschliche oder automatische Anmerkungen ist von Situation zu Situation unterschiedlich.
Die meisten Unternehmen verwenden halbautomatische Annotationsstrategien, die den automatisierten ML-Prozess mit manuellen Beschriftungsansätzen kombinieren.
Datenannotation und Datenetikettierung sind nicht das Gleiche. Die Begriffe werden häufig vertauscht. Aber obwohl beide den gleichen Stil und die gleiche inhaltliche Kennzeichnung verwenden, unterscheiden sie sich in einzelnen Punkten:
Nachdem Sie nun eine klare Vorstellung von der Datenkommentierung haben und wissen, warum sie für Ihre ML-Projekte notwendig ist, geht es nun darum, sie richtig zu nutzen. Wenn Sie das Beste aus der Datenkommentierung herausholen wollen, müssen Sie diese als Teil Ihres ML-Workflows sehen.
Dazu müssen Sie eine Mischung aus Softwareelementen, Algorithmen, Annotatoren usw. entwickeln. Außerdem müssen Sie sich zwei Fragen für Ihr Datenannotationsprojekt stellen:
Sie können verschiedene Techniken anwenden, um diese Probleme zu lösen. Damit Sie sich ein besseres Bild machen können, geben wir Ihnen einen Überblick über die beiden wirksamsten Techniken:
Aktives Lernen vermittelt Ihnen die Methoden, mit denen Sie die Daten für die Annotation auswählen können. Bei der Qualitätsbewertung geht es um die Validierung der Annotationsleistung.
Aktives Lernen bezieht sich auf die Auswahl von Datenproben, wobei die Datenkommentierung im Vordergrund steht. Vor der Kombination von menschlichen Annotationen mit ML-Modellen muss entschieden werden, welche Elemente der Daten von Menschen annotiert werden sollen.
Die für die Datenkommentierung erforderlichen Ressourcen sind meistens knapp. Sie müssen also effektiv genutzt werden. Hierfür können Sie zwischen verschiedenen Arten des aktiven Lernens für die Datenkommentierung wählen, um Zeit und Geld zu sparen. Nachfolgend finden Sie die drei gebräuchlichsten Methoden, die von den meisten Benutzern verwendet werden.
Diversity Sampling bezieht sich auf das allgemeine Paradigma, das versucht, unterrepräsentierte oder unbekannte Werte in Ihrem Modell zu entdecken. Es kann sich als nützlich erweisen, wenn Sie aus verschiedenen Optionen wählen müssen. Es ist auch bekannt als:
Einer der Hauptvorteile dieses Tools besteht darin, dass es dem Modell ermöglicht, aus unterrepräsentierten Informationen und Details zu lernen. In manchen Fällen ignorieren ML-Modelle bestimmte Informationen in den Datensätzen, wenn diese nur selten vorkommen. Das Diversity Sampling ermöglicht es ihnen jedoch, auch aus solchen Informationen zu lernen.
Darüber hinaus hilft Diversity Sampling, Leistungsverluste aufgrund von Datendrift zu vermeiden. Dies geschieht in der Regel, wenn das KI- oder ML-Modell zu viele Daten aus den alten und ungenauen Probenregionen enthält.
Unter Uncertainty Sampling versteht man die Auswahl unbeschrifteter Stichproben, die nahe an der Entscheidungsfähigkeit des Modells liegen. Der Vorteil dieser Methode besteht darin, dass Sie Stichproben identifizieren können, bei denen eine höhere Wahrscheinlichkeit besteht, dass sie falsch klassifiziert werden. So können Sie diese manuell mit Anmerkungen versehen, um die Fehlerquote zu verringern.
Die Zufallsstichprobe ist ebenfalls eine Art des aktiven Lernens. Sie ist die einfachste Methode, die Sie anwenden können. Die einzige Herausforderung besteht darin, eine Zufallsstichprobe zu finden. Das kann aufgrund der Verteilung der erhaltenen Daten schwierig sein. Außerdem gibt es bestimmte Probleme, die man mit anderen Methoden lösen kann, aber nicht mit der Zufallsstichprobe.
Sobald Sie die Stichprobenprüfung abgeschlossen haben, muss als Nächstes eine angemessene Qualitätssicherung erfolgen. Denn Menschen können Fehler machen. Daher ist die Einführung geeigneter Kontrollpunkte zur Identifikation dieser Fehler wichtig. Im Folgenden haben wir einige Punkte aufgeführt, die Ihnen dabei helfen, die Annotationsleistung zu verbessern:
In einer Übersicht sind hier die vier besten Praktiken für den Umgang mit dem Qualitätssicherungsprozess aufgelistet. Die Abteilung Global Data von Bloomberg sammelt diese Verfahren. In der folgenden Tabelle werden die Qualitätsbewertungsmethoden, ihre Vorteile und ihre Nachteile erläutert.
Name | Prozess | Vorteile | Nachteile | |
Zufällige QA | Stichprobe nach Zufall |
|
| |
Gold-Aufgabe | Bereiten Sie die Arbeitsaufgaben vor und vergleichen Sie sie direkt mit den kommentierten Antwortschlüsseln. |
|
| |
Redundante Beschriftungen mit gezielter QA | Durchführung verschiedener Anmerkungen und ordnungsgemäße QS bei nicht übereinstimmenden Ergebnissen |
|
| |
Anmerkungsredundanz mit Nachkontrolle | Durchführung verschiedener Anmerkungen und Erörterung der Leitlinien, die die Annotatoren anwenden |
|
|
Die Datenkommentierung ermöglicht es den KI- und ML-Modellen zu verstehen, ob es sich bei den Daten, die sie erhalten, um Audio-, Video-, Bild-, Text-Daten oder um eine Kombination all dieser Formate handelt. Je nach Spezifikationen und den festgelegten Parametern kategorisiert das Modell die Daten und führt die entsprechenden Aufgaben aus.
Datenkommentierung stellt sicher, dass Ihr Modell richtig trainiert wird, so dass es langfristig die besten Ergebnisse erzielt. Die Datenkommentierung liefert Ihnen ein perfektes Modell für jede Aktivität, unabhängig davon, ob Sie Bilderkennung oder Chatbots verwenden.
Der Begriff menschliche Datenkommentare (Human Annotated Data) bezeichnet das Hinzufügen von Metadaten oder anderen Informationen zu Daten durch Menschen. Hier sind einige gängige Beispiele für menschliche Datenkommentare:
Die Annotation von Daten durch den Menschen hat mehrere Vorteile, unter anderem:
Es gibt mehrere Gründe dafür, Daten mit Anmerkungen von Menschen zu versehen, zum Beispiel:

