Clickworker

Die industrialisierte Welt ist voll von Maschinen, die den Menschen in Stärke und Geschwindigkeit übertreffen. Kräne heben Stahlträger in die Höhe, Motoren lassen Autos unvorstellbare Geschwindigkeiten erreichen und Holzschredder pulverisieren im Handumdrehen ganze Kiefernstämme. Solche Erfindungen replizieren und übertreffen den Menschen bei Aufgaben, die körperliche Anstrengung erfordern. Sie besitzen „künstliche Muskeln“.
Zuallererst können wir uns KI als eine Maschine (d.h. einen Computer) vorstellen, die menschliche kognitive Aufgaben nachbildet. Ein Taschenrechner zum Beispiel verkörpert eine grundlegende KI, für die der Mensch sein Gehirn benutzen muss: Mathematik.
Während Definitionen von „künstlicher Intelligenz“ reichlich vorhanden sind, erklären die Vorreiter der Disziplin, Peter Norvig und Stuart Russell, sie treffend, wenn sie von „rationalen Agenten“ sprechen. Ein rationaler Agent, sagen sie, „handelt, um das beste Ergebnis zu erzielen, oder, wenn es Unsicherheiten gibt, das beste erwartete Ergebnis“. Die meisten Untersuchungen zur KI passen in irgendeiner Weise in die Beschreibung des „rationalen Agenten“.
Wie unterscheiden sich „beste“ und „am besten erwartete“ Ergebnisse? Ein optimales Ergebnis kann als solches nachgewiesen werden. Aber anhand von besten erwarteten Ergebnissen kann man nicht erkennen, ob eine Antwort, Lösung oder Aktion einer anderen überlegen ist. Zum Beispiel, wenn jemand eine Golfhändler-Website besucht und den Chatbot auf der Website fragt: „Wann schließt Ihr Standort in San Francisco heute?“ In diesem Fall gibt es nur eine richtige Antwort: 21 Uhr. Wir können überprüfen, ob der Chatbot die beste Entscheidung getroffen hat.
Aber wenn die Person sagt, „Ich habe heute einen meiner Schläger kaputt gemacht. Was soll ich tun“, ist unklar, wie der Chatbot reagieren soll. Ein rationaler Chatbot würde in diesem Fall Daten aus früheren Kundeninteraktionen nutzen, um entsprechende klärende Fragen zu stellen.
Herkömmliche KI-Systeme sind vorprogrammiert oder „fest programmiert“, um spezifische Probleme zu lösen. Entwickler schreiben eine immense Anzahl von „Wenn-dann“-Logikanweisungen in die Algorithmen. Da herkömmliche oder symbolische KI-Systeme nur das tun können, wofür sie explizit programmiert wurden, und Programmierer nicht unendlich viele Codes schreiben können, ist der Kompetenzbereich für diese Systeme recht limitiert. Von der kolossalen Menge an menschlicher Arbeit, die sie erfordern, ganz zu schweigen.
Bestimmte Schachcomputer sind zum Beispiel fest programmiert. In diesem Szenario kann ein Datenwissenschaftler mit einem erfahrenen Schachspieler zusammenarbeiten und einzelne Schachzüge in das KI-System eingeben. Durch das Befolgen dieser vordefinierten Befehle kann ein KI-Agent ziemlich gut spielen. Aber er kann nicht viel mehr. Wenn Sie ihn fragen würden, wer Nelson Mandela ist, würde er schweigen.
Um der Intelligenz eines Menschen gerecht zu werden, muss sich ein KI-Agent Allgemeinwissen aneignen und sich in mehreren Bereichen auskennen. Machine Learning ist der Zweig der KI, der versucht, Computer mit dieser breiteren Kompetenz auszustatten.
Beim Machine Learning diktiert der Datenwissenschaftler nicht jede Aktion des KI-Systems durch mühsame Vorprogrammierung, sondern erstellt einen „Lernalgorithmus“, der dem KI-Agenten das Lernen beibringt.
Auch Modell genannt, muss ein maschineller Lernalgorithmus mit großen Datenmengen trainiert werden. Einem Modell beizubringen, Schach zu spielen, bedeutet zum Beispiel, es mit Tausenden von Videos verschiedener Schachzüge als Lernmaterial zu versorgen. Im Laufe der Zeit lernt das Modell, das Spiel zu spielen – oft auf elitärer Ebene – indem es Muster in den Daten erkennt.
Machine Learning Modelle bieten uns Services wie Spam-Filter, personalisierte Empfehlungen auf Websites und automatisierte Identitätsüberprüfungsdienste. Sie ermöglichen uns auch, mit erstaunlicher Genauigkeit vorherzusagen, wann unser Produktbestand zur Neige geht oder der Strom ausgeht oder die Preise fallen.
Generell gibt es zwei Möglichkeiten, die Algorithmen eines Machine Learning Modells zu trainieren: mit überwachtem oder unüberwachtem Lernen
Beim überwachten Lernen kennzeichnen Sie die Trainingsdaten. Anders ausgedrückt, Sie geben dem Modell einen Lösungsbogen. Wenn Sie zum Beispiel einen KI-Agenten trainieren würden, ein Auto von einem Flugzeug zu unterscheiden, indem Sie nur Textdaten verwenden, würden Sie zuerst die verschiedenen „Merkmale“ Ihrer Daten zusammenstellen und beschriften. Ein Merkmal in den Daten kann die Geschwindigkeit (Merkmal 1) und das Gewicht (Merkmal 2) des Fahrzeugs enthalten. Als nächstes würden Sie Ihr KI-Modell mit – im Idealfall – Tausenden von weiteren solcher Datensätze speisen. Schließlich würde der Algorithmus die drastischen Geschwindigkeits- und Gewichtsunterschiede zwischen den beiden Fahrzeugtypen erfassen und lernen, Autos und Flugzeuge selbstständig zu erkennen.
Beim unüberwachten Lernen fehlt der Spickzettel. Während Sie den Algorithmus auch hier mit Datensätzen von Merkmalen speisen, lassen Sie die Lösungen weg. In diesem Zusammenhang können Sie das Modell so programmieren, dass es bestimmte Ergebnisse findet, indem es die Datensätze durchkämmt, oder die Daten nach den gefundenen Mustern „zusammenfasst“. Wissenschaftler nutzen diese Methode bei der genomischen Sequenzierung. Sie füttern maschinelle Lernmodelle mit riesigen, unmarkierten Datensätzen, die genetische Informationen enthalten, und erlauben es dem Modell, bestimmte DNA in Clustern zu sammeln, die auf gemeinsamen Merkmalen basieren.
Genomische Sequenzierung, so stellt sich heraus, erfordert viel mehr Rechenleistung und analytische Tiefe als herkömmliche Anwendungsfälle des Machine Learning. Für ein solch massives Unterfangen verwenden die Forscher eine fortgeschrittene Form des Machine Learning, das so genannte Deep Learning.
Deep Learning stützt sich auf riesige Datenmengen, riesige Reserven an Rechenleistung und ausgefeilte Machine Learning Techniken, um einige der bisher größten Erfolge der KI zu erzielen – Google’s Deep Learning Agent AlphaGo schlägt den Weltmeister von Go, einem komplexen Brettspiel, und ist nur ein Beispiel dafür.
Die Algorithmen eines Deep-Learning-Modells sind in einem neuronalen Netzwerk angeordnet, ein charakteristisches Merkmal des Deep-Learning. Neuronale Netze imitieren den Prozess des menschlichen Gehirns, in dem bestimmte neuronale Verbindungen stärker werden, wenn das Gehirn auf Reize reagiert.
Die Neuronen des tiefen Lernens werden Knoten genannt, und sie belegen mehrere Schichten innerhalb eines Modells. Ein Knoten in der ersten Schicht verbindet sich mit einem oder mehreren Knoten in der zweiten Schicht und so weiter. Dabei wird jeder Knotenverbindung eine Gewichtung zugewiesen, die bei der Aggregation weitgehend die Ausgabe des Modells bestimmt.
Neuronale Netze sind in der Praxis viel einfacher zu verstehen. Wenn man ein tiefgehendes Lernmodell trainieren will, um viktorianische Häuser auf Fotos zu erkennen (eine Fähigkeit, die als Bildklassifikation bekannt ist) zeigt man dem Modell ein Foto. Die Knoten auf der ersten Ebene beginnen dann „einfache Merkmale“ im Bild zu identifizieren, wie z.B. eine Farbe, eine Textur oder eine flache Kante. Diese Knoten geben dann das Gelernte an ihre Kollegen in der nächsten Ebene weiter. Jeder Knotenverbindung sind gleichzeitig Gewichtungen zugeordnet.
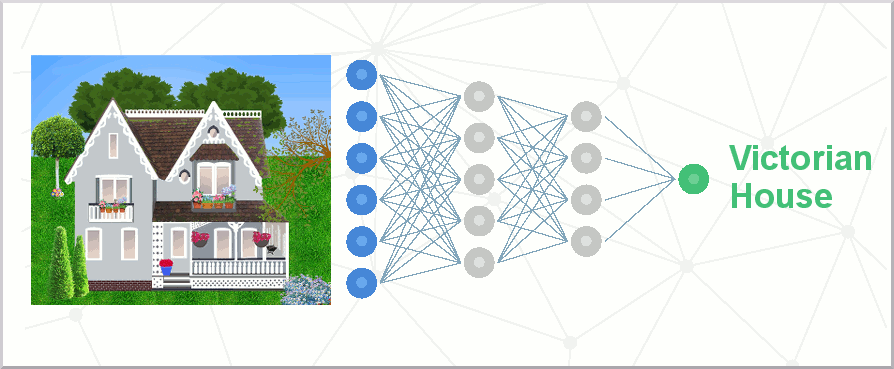
Das Bild wird klarer, da die Informationen über immer mehr Ebenen verknüpft werden. Ab einem bestimmten Punkt kann das Modell z.B. beginnen, ein schiefes Erkerfenster auf dem Foto zu erkennen. Schließlich, wenn die Knoten auf allen Ebenen das Foto zerlegt haben, und alle Gewichtungen berücksichtigt wurden, wird das Modell des Deep-Learning seine Antwort liefern (Ausgabe). Es kann erklären, dass es 95% sicher ist, dass auf dem Bild ein viktorianisches Haus zu sehen ist, 3% sicher, dass zudem ein Handwerker zu sehen ist, und 2% sicher, dass auf dem Bild auch Ziegel zu sehen sind. Informatiker werden dann die Gewichtungen anpassen, um die Genauigkeit des Modells für zukünftige Iterationen zu optimieren.
Zum Glück ist der Nutzen des Deep-Learning nicht auf die vergangenen Modelle und Konstruktionen beschränkt. Deep-Learning Methoden werden weiterentwickelt und wurden u.a. bereits im Gesundheitswesen eingesetzt, um zum Beispiel Krebszellen im menschlichen Gewebe zu erkennen. Einige KI-Agenten haben sogar Ärzte in diesem Bereich übertroffen.
Über die medizinische Bildgebung hinaus werden Deep Learning-Modelle verwendet, um alle möglichen Arten von Daten zu verarbeiten – nicht nur Fotos – und treiben den Fortschritt im Bereich Cyberbetrugsschutz, pharmazeutische Forschung, selbstfahrende Autos, prädiktive Analysen und vieles mehr voran.
Moderne KI-Systeme brauchen riesige Massen an hochwertigen Daten, um zu lernen, wie man sich rational verhält. Ohne die Zunahme von Big Data würden wir uns immer noch in Richtung rudimentärer Meilensteine des maschinellen Lernens bewegen. Doch die Beschaffung reichhaltiger Daten ist für viele Forscher und Datenwissenschaftler eine Herausforderung. Selbst wenn sie über Tausende von Daten verfügen, fehlt ihnen möglicherweise die Zeit und das Personal, um die Daten zu markieren/labeln.
Hier kann clickworker, ein Anbieter von KI-Trainingsdaten über Crowdsourcing, Ihnen helfen und große Mengen hochwertiger Daten liefern. Clickworker bietet bedarfsspezifische Trainingsdaten, einschließlich Texten, Web-Recherche-Daten, Bildannotationen, Fotos, Video- und Sprachaufzeichnungen / Audio-Datensätze. Unabhängig davon, ob Sie ein KI-Modell für die Verarbeitung natürlicher Sprache, prädiktive Analysen, Bildklassifizierung oder etwas anderes konzipieren, mit den Datensätzen von clickworker können Sie Ihr Modell schnell und optimal trainieren sowie Fehlerquoten minimieren.
KI Trainings-Daten-Service von clickworker
Klicken Sie auf diesen Link „KI Trainings-Daten von clickworker“ oder rufen Sie direkt bei clickworker an (+49 201 9597180), um mehr über den Service zu erfahren.
Die nächste Welle von Durchbrüchen der Entwicklung von KI-Systemen kann in einigen Fällen nicht früh genug kommen. Die Hoffnung der Entwickler von künstlicher Intelligenz besteht darin, dass sie der Menschheit große Lasten abnimmt und zur Lösung unserer schwierigsten Herausforderungen beiträgt. Wenn wir diese Ziele erreichen wollen, brauchen wir viele Trainingsdaten. So viel ist sicher.

Clickworker

