
Wenn die meisten Menschen über künstliche Intelligenz (KI) nachdenken, stellen sie sich zwei mögliche Zukunftsvisionen vor. Eine positive Zukunft, in der selbstfahrende Autos uns bei der Navigation auf unseren Straßen helfen und Roboter uns bei der Instandhaltung unserer Häuser unterstützen. Oder eine eher negative, in der Maschinen uns die Arbeitsplätze wegnehmen.
Glücklicherweise sieht es so aus, als müssten wir uns um die negative Vision keine Sorgen machen. KI-Systeme werden den Menschen in der Arbeitswelt nicht ersetzen, sondern vielmehr als unschätzbare Helfer an seiner Seite existieren. Während selbstfahrende Autos auf dem besten Weg sind, Realität zu werden, warten einige unserer anderen grandiosen Ziele für die KI noch auf ihre Verwirklichung, doch bis es soweit ist, muss noch einiges getan werden.
Das Stadium, in dem wir uns jetzt befinden, ist nicht über Nacht entstanden. KI-Systeme mussten trainiert werden, damit sie uns die Vorteile bieten können, an die wir uns bereits gewöhnt haben.
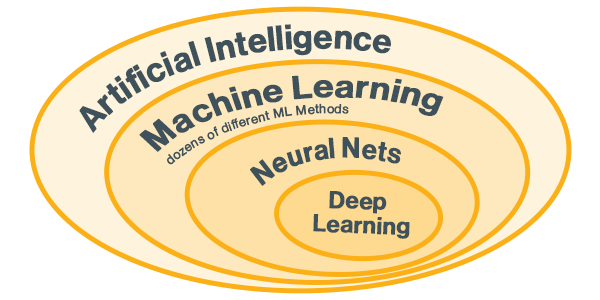
Maschinelles Lernen, Deep Learning und künstliche Intelligenz sind miteinander verknüpfte Konzepte.
Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz, der es Computern ermöglicht, automatisiert zu lernen, sich zu verbessern und Fähigkeiten zu verfeinern, je nachdem, womit sie konfrontiert werden. Beim maschinellen Lernen werden Algorithmen verwendet, die Beziehungen zwischen Variablen (d. h. Muster) entdecken und dann aus diesen Lektionen lernen, je mehr Daten sie erhalten – ganz ähnlich wie Kinder durch Erfahrung lernen.
Da die Algorithmen des maschinellen Lernens Milliarden von Datenpunkten verwenden, die der Mensch nicht verstehen oder im Detail interpretieren muss, sind sie gut in der Lage, Muster in Datensätzen zu finden, indem sie Techniken wie die überwachte oder unüberwachte Klassifizierung anwenden.
Tiefe neuronale Netze sind eine speziellere Technik des maschinellen Lernens, die das menschliche Gehirn bei der Verarbeitung von Daten nachahmt. Die Computer lernen durch positive und negative Verstärkung und stützen sich auf eine kontinuierliche Verarbeitung und Rückmeldung.
Deep Learning stützt sich auf ein hochgradig geschichtetes Netzwerk aus tiefen neuronalen Pfaden. Jedes Neuron des Netzwerks, bestehend aus einer mathematischen Funktion , die mit Daten gefüttert ,umgewandelt und als Ausgabe analysiert wird, erzeugt komplexe Muster und Assoziationen.
In jedem Zyklus lernt der Computer, die Bedeutung jeder Verbindung zwischen den Neuronen zu gewichten. Der Computer wird besser darin, vorherzusagen, was passieren wird, wenn viele Variablen und veränderte Bedingungen vorliegen.
Mit der jüngsten Steigerung der Computerleistung haben neuronale Netze neue Lernmethoden integriert, die die Leistungsfähigkeit von KI-Modellen erhöhen, da sie nun in der Lage sind, schwierige Mustererkennungsaufgaben zu bewältigen.
Das Training von KI ist ein hochkomplexer und faszinierender Prozess. Auf dem Gebiet der KI-Forschung wird kontinuierlich daran gearbeitet, die besten Strategien zur Verbesserung der Modellgeschwindigkeit und -genauigkeit zu finden.
Das KI-Training ist ein dreistufiger Prozess. Im ersten Schritt, dem Training, wird ein Computeralgorithmus mit Daten gefüttert, um Vorhersagen zu erstellen und deren Genauigkeit zu bewerten. Im zweiten Schritt, der Validierung, wird bewertet, wie gut das trainierte Modell bei zuvor ungesehenen Daten abschneidet. Schließlich wird getestet, um herauszufinden, ob das endgültige Modell mit neuen Daten, die es noch nie gesehen hat, genaue Vorhersagen trifft.
In diesem Beitrag werden wir jeden dieser Schritte genauer untersuchen und erklären, wie sie miteinander interagieren.
Tipp:
Passende Trainingsdaten für Ihr KI-System erhalten Sie bei clickworker.
KI-Trainingsdaten
Erfahren Sie mehr zum Service
Der erste Schritt beim KI-Training besteht darin, Daten in ein Computersystem einzuspeisen. Dies veranlasst das System, Vorhersagen zu treffen und die Genauigkeit bei jedem neuen Zyklus zu bewerten oder alle verfügbaren Datenpunkte durchzugehen. Durch den Einsatz von Techniken des maschinellen Lernens (ML), einschließlich Deep Learning, kann der Algorithmus die Daten analysieren und bessere Vorhersagen treffen.
Auf diese Weise bringen wir der Software bei, wie sie verschiedene Merkmale in einem Bild erkennen kann, z. B. den Hautton oder die Haarfarbe. Im Laufe der Zeit werden diese anfänglichen Vermutungen immer genauer, bis sie einen Punkt erreichen, an dem es nicht mehr viel Raum für Verbesserungen gibt.
Um dieses Stadium zu erreichen, werden riesige Mengen an Daten in das Modell eingespeist. Diese Daten können viele verschiedene Formate haben, je nachdem, was analysiert werden soll. Wenn beispielsweise ein Algorithmus für die Gesichtserkennung entwickelt werden soll, werden verschiedene Gesichter in das Modell geladen.
Es ist wichtig zu wissen, wie Sie das Modell trainieren wollen, denn je nachWahl müssen die Daten möglicherweise kategorisiert und gelabelt werden, damit der Algorithmus besser entscheiden kann. Es gibt zwei Hauptmethoden für das KI-Training. Ein überwachter Lernalgorithmus benötigt gelabelte Eingabe- und Ausgabedaten, ein nicht überwachter hingegen nicht.
Beim überwachten Lernen „lernt“ der Algorithmus aus dem Trainingsdatensatz, indem er durch eine Vorhersage unbekannter Variablen iteriert. Bei überwachten maschinellen Lernmodellen ist menschliche Arbeit erforderlich, um das Computersystem zu „trainieren“, indem geeignete Kennzeichnungen für die Eingabedaten bereitgestellt werden. Um auf unser vorheriges Beispiel zurückzukommen: Bei einem überwachten Lernmodell würden die Gesichter, die eingegeben werden, entsprechend gelabelt werden, und auch andere Elemente würden mit den richtigen Bezeichnungen eingegeben werden. Auf diese Weise würde eine Spiegelung in einem Fenster nicht mit einer Person verwechselt werden. Ein weiteres Beispiel für ein Modell mit überwachtem Lernen ist eine Reisevorhersage auf der Grundlage eines täglichen Pendelwegs. Indem das Modell darauf trainiert wird, die Auswirkungen des Wetters und der Tageszeit zu verstehen, kann es genauere Vorhersagen auf der Grundlage der aktuellen Bedingungen machen.
Modelle für unüberwachtes Lernen arbeiten unabhängig voneinander, um Strukturen zu finden, die in nicht gelabelte Daten vorhanden sein könnten. Diese Mustererkennung kann nützlich sein, um Korrelationen in Daten zu finden, die nicht sofort offensichtlich sind, und Ausreißer zu identifizieren, die eine weitere Untersuchung wert sind. Unüberwachte Lernmodelle sind wesentlich schneller zu trainieren, erfordern aber immer noch menschliche Eingriffe zur Validierung der Ausgabevariablen.
Die drei Arten des unüberwachten Lernens sind Clustering, Association Rule Mining (Assoziationsregel-Mining) und Ausreißererkennung.
Eine neuere Untergruppe des unüberwachten Lernens ist als Reinforcement Learning (Verstärkungslernen) bekannt. Verstärkungslernen ist eine Art des maschinellen Lernens, bei dem durch Belohnungen und Bestrafungen versucht wird, eine Belohnungsmetrik zu maximieren. Diese Art des Lernens wird am häufigsten für Spiele und selbstfahrende Autos verwendet.
Sobald die Daten in das Modell geladen worden sind, kann die nächste Phase des Trainings beginnen.
Der zweite Schritt bei der KI-Schulung ist der Validierungstest, bei dem bewertet wird, wie die Modelle bei Daten abschneiden, die das Modell noch nicht gesehen hat. Ein Validierungstest wird verwendet, um zu bewerten, wie gut ein trainiertes Modell mit ungesehenen Daten abschneidet, was dabei helfen kann, festzustellen, ob das Training fortgesetzt oder in irgendeiner Weise verändert werden muss.
Reinforcement-Learning-Modelle werden bewertet, indem sie versuchen, ihre zukünftige Belohnungsmetrik zu maximieren – sie fahren also fort, bis es kein Verbesserungspotenzial mehr gibt. Im Gegensatz dazu haben überwachtes Lernen und unüberwachtes Lernen begrenzte Endpunkte, bei denen die Größe des Datensatzes vorgibt, welche Gewichte zugewiesen bzw. validiert werden sollten.
Eine gängige Strategie ist das so genannte „frühzeitige Abbrechen“, bei dem aufgrund der Leistungsbewertung erkannt wird, dass weitere Änderungen die Vorhersagen angesichts der verfügbaren Ressourcen (z. B. Zeit) wahrscheinlich nicht sinnvoll verbessern werden. Wenn dies der Fall ist, ist es oft eine gute Idee, das Training abzubrechen und andere Optionen zu untersuchen.
Nun ist es an der Zeit, von der Simulation in die reale Welt zu wechseln. Geben Sie der KI einen Datensatz, der keine Tags oder Ziele enthält (diese haben ihr bisher bei der Interpretation der Daten geholfen). Nachdem Sie Ihre KI auf unstrukturierte Informationen trainiert haben, ist es an der Zeit, sie auf die Probe zu stellen.
Je genauer die Entscheidungen sind, die Ihre künstliche Intelligenz treffen kann, desto besser sind Sie vorbereitet, wenn sie in Betrieb geht. Allerdings müssen Sie genauer hinschauen, ob Sie auch eine 100-prozentige Genauigkeit erreichen.
Eine der klassischen Herausforderungen bei der KI-Schulung ist die Überanpassung, bei der Ihre Anwendung bei Trainingsdaten gut, bei neuen Daten aber weniger gut abschneidet. Auf der anderen Seite der Skala bedeutet Unteranpassung, dass Ihre Modelle beim Jonglieren mit alten und neuen Daten nicht gut abschneiden. Wenn das Modell in dieser Phase nicht wie vorhergesagt funktioniert, kehren Sie zum Trainingsprozess zurück und wiederholen ihn, bis Sie mit der Genauigkeit zufrieden sind.
Sobald Sie ein Modell haben, das den Trainings- und Validierungsprozess bestanden hat, kann es verlockend sein, sich zurückzulehnen und sich auf seinen Lorbeeren auszuruhen. Die Realität ist jedoch, dass Modelle ihre Umgebung nachahmen und im Idealfall diese sich verändernde Welt widerspiegeln sollten. Damit die Tests erfolgreich sind, müssen bestimmte Kriterien erfüllt sein:
Die Daten, die zum Trainieren Ihres Algorithmus verwendet werden, müssen genau und relevant sein. Wenn Ihre Daten mit Tags versehen (strukturiert) sind, müssen die Tags einem Interessenbereich zugeordnet werden. Wenn Sie beispielsweise versuchen, eine KI für den Kundendienst zu trainieren, die Fragen zu Ihrem Produktsortiment beantworten kann, dann ist es wichtig, dass diese Tags „Produkt A“ oder „Produkt B“ enthalten. Je genauer die eingegebenen Daten sind, desto schneller wird der Trainings- und Validierungsprozess verlaufen.
Derzeit ist es nicht möglich, automatisch Annotationen für erstklassige Daten zu erstellen, die keine manuelle Arbeit erfordern. Durch die Bereitstellung großer Mengen bereinigter und getaggter Daten für einen Pool von Experten aus verschiedenen Bereichen auf Crowdsourcing-Plattformen kann die Zeit für Ihr Projekt jedoch ohne Qualitätseinbußen verkürzt werden.
Deep Learning ist ein intensiver Prozess für den Computer und hat viel mit dem menschlichen Lernen gemeinsam. Dieser Prozess erfordert große Mengen an Rechenleistung, z. B. leistungsstarke Grafikprozessoren (GPUs) in Kombination mit Clustern oder Cloud Computing für große Trainingsdatensätze.
Die Einrichtung von Systemen mit mehreren Grafikprozessoren oder in einem Cluster kann dazu beitragen, den Deep Learning-Prozess zu beschleunigen.
Eine Entscheidung in Bezug auf die KI-Infrastruktur kann Überlegungen wie Datenspeicherung, Rechenressourcen oder Zeit beinhalten. Der Aufbau und die Pflege einer eigenen Computerinfrastruktur ist ein anspruchsvolleres Unterfangen als die Anmietung von Webserverplatz bei einem Anbieter. Es lohnt sich aber auch in mehrfacher Hinsicht, unter anderem wegen der Flexibilität. Für den Einstieg in die künstliche Intelligenz ist ein Cloud-Anbieter möglicherweise die beste Option, da er den Einstieg erleichtert und gleichzeitig die erforderlichen Vorteile bietet.
Neben den Überlegungen zur Hardware muss auch die Frage der Software, der Algorithmen und der Partner berücksichtigt werden. Praktisches maschinelles Lernen stützt sich auf überwachte Lernalgorithmen, bei denen es sich in der Regel um lineare Regressionsalgorithmen für Regressionsprobleme und um Support-Vektor-Maschinen für die Klassifizierung handelt.
Wenn Sie jedoch keine Daten über das gewünschte Ergebnis haben, sollten Sie unkategorisiertes Lernen verwenden. Ein beliebtes Beispiel ist der k-means-Algorithmus für Clustering, der mit einer einfachen Heuristik und einer Schätzung , die zu bildenden Cluster trainiert.
Eine weitere Überlegung in Bezug auf die KI-Schulung ist die Frage, wer den Algorithmus trainieren soll. Weltweit gibt es einen Mangel an KI-Entwicklern, und die wenigen, die nicht beschäftigt sind, erhalten hohe Gehälter. Renommierte Technologieunternehmen rekrutieren aktiv an Spitzenuniversitäten in aller Welt, um Absolventen abzuwerben und so den Bedarf zu decken. Entwickler müssen eine Vorliebe für C++-Programmierung, STL, Physik oder Biowissenschaften haben. Folglich haben Schulen, die sich auf MINT-Fächer spezialisiert haben, immer früher damit begonnen, Studenten einzustellen, um sie auf die Arbeit im Bereich der KI und der Datenwissenschaften vorzubereiten.
Echte KI liegt noch in weiter Ferne, und auch wenn die Forscher weiterhin Fortschritte machen, ist die Angst vor der Roboter-Apokalypse nicht angebracht. Vielmehr wird die KI immer nützlicher werden, da Unternehmen und Einzelpersonen immer neue Anwendungsfälle und -möglichkeiten finden.
Mit der Weiterentwicklung von KI-Schulungstools, -Hardware und -Verfahren wird sich wahrscheinlich auch die Revolution der künstlichen Intelligenz weiterentwickeln.


