
RAG (Retrieval-Augmented Generation) kombiniert die Leistungsfähigkeit großer Sprachmodelle (LLMs) mit externen Wissensabfragen. Was sollte man darüber wissen? Erfahren Sie mehr über diese fortschrittliche KI-Architektur – Funktionsweise, Bedeutung, Geschäftsanwendungen und mehr.
Die Schwächen aktueller KI-Systeme sind bekannt. Ein Aspekt ist dabei besonders frustrierend: Man kann sich nicht auf die Genauigkeit von Informationen verlassen. Aktuelle LLMs „halluzinieren“ häufig Fakten, Personen, Code-Bibliotheken oder Ereignisse – und präsentieren diese Informationen so selbstsicher, dass Fehler schwer zu erkennen sind. Dieses Problem kann mit hochwertigen KI-Trainingsdaten und Feinabstimmung reduziert werden. Eine weitere leistungsstarke Lösung ist RAG.
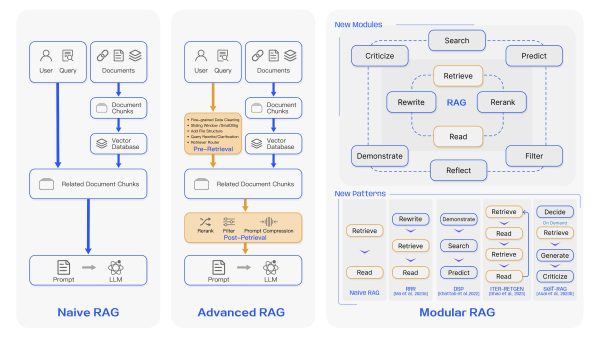
RAG ist ein hybrides KI-System, das traditionelle Sprachmodelle verbessert. Zu diesem Zweck führt es einen zusätzlichen Retrieval-Schritt ein, um relevante Informationen aus externen Quellen abzurufen. Dies geschieht, bevor Antworten generiert werden. Dadurch kann die KI auf aktuelle, faktenbasierte Informationen zugreifen und ist nicht mehr ausschließlich auf die ursprünglichen Trainingsdaten angewiesen.
Wichtige Erkenntnisse
- RAG (Retrieval Augmented Generation) ist eine KI-Architektur, die große Sprachmodelle (LLMs) mit externer Wissensabfrage kombiniert, um genaue und verlässliche Informationen bereitzustellen.
- Dieser Ansatz minimiert KI-„Halluzinationen“, ermöglicht den Zugriff auf aktuelle Daten und verbessert die Überprüfbarkeit durch Quellenangaben.
- RAG-Systeme sind besonders wertvoll in Geschäftsanwendungen wie Kundenservice, Wissensmanagement und personalisiertem Marketing.
- Die Herausforderungen für RAG sind Skalierbarkeit, kontextuelles Verständnis und die Integration verschiedener Wissensquellen.
- GraphRAG, eine fortschrittliche RAG-Variante, nutzt Wissensgraphen zur Verbesserung des Kontextverständnisses und der Skalierbarkeit. GraphRAG hat das Potenzial, traditionelle RAG-Beschränkungen zu überwinden.
RAG macht KI nicht nur verlässlicher, sondern führt auch eine Überprüfbarkeit ein. Einfach ausgedrückt: Man kann auf einen Link zur Quelle klicken, um diese selbst zu überprüfen. Ein Beispiel: Perplexity, eine RAG-Anwendung, die auch eine Websuche kombiniert. Sie zeigt in einer Liste an, auf welchen Quellen bestimmte Informationen basieren:

Bildquelle: Baoyu, Prompt Engineer
Durch den Einsatz von Retrieval Augmented Generation schaffen Unternehmen intelligentere, anpassungsfähigere und vertrauenswürdigere KI-Systeme. Sie erhöhen dadurch ihr Wachstumspotenzial, ermöglichen bessere Kundenerfahrungen treiben ihre betriebliche Effizienz voran.
RAG-basierte KI-Assistenten eröffnen neue Geschäftsmöglichkeiten. Denn sie verbessern die Produktivität im Vergleich zu traditionellen großen Sprachmodellen (LLMs) erheblich. RAG ermöglicht es KI-Systemen, auf große Wissens- und Codebasen zuzugreifen und diese zu nutzen, um genauere und zuverlässige Antworten zu liefern. Dies schafft Möglichkeiten für Unternehmen, spezialisierte KI-Assistenten zu entwickeln, die auf bestimmte Domains, Branchen oder Unternehmensumgebungen zugeschnitten sind.
Cursor AI ist ein weiteres Beispiel für RAG. Es speichert eine Codebasis sowie API- und Bibliotheksdokumentation, um den richtigen Kontext für LLMs bereitzustellen. Diese können dann neuen Code generieren oder bestehende Teile bearbeiten:
Ein interessantes Geschäftsmodell ist die Entwicklung fortschrittlicher Kontext-Engines und Abfragesysteme. Für die Leistung von RAG kommt es darauf an, mehrere „Linsen“ oder Kontextanbieter zu haben, die schnell relevante Informationen aus verschiedenen Quellen ziehen können. Unternehmen, die leistungsstarke Code-Suchindizes, natürliche Sprachsuche und Verbindungen zu verschiedenen Datenquellen entwickeln können, werden in diesem Bereich gut positioniert sein. Es gibt auch Potenzial für die Erstellung branchenspezifischer oder Domain-spezifischer Wissensbasen, die zur Ergänzung allgemeiner LLMs verwendet werden können.
Der Übergang zu agentischen Workflows, die durch Retrieval Augmented Generation ermöglicht werden, schafft Möglichkeiten für Automatisierungen und den effektiven Einsatz von Produktivitätstools. Iterative KI-Agenten, die planen, Unteraufgaben ausführen und ihre eigene Arbeit ständig verfeinern, erzielen deutlich bessere Ergebnisse als einfache LLM-Antworten. Viele Unternehmen nutzen heute spezialisierte Agenten für Aufgaben wie Forschung, Kodierung, Datenanalyse oder das Verfassen von Texten. RAG erleichtert autonomes Arbeiten und sichert qualitativ hochwertigere Ergebnisse. Es gibt auch Potenzial für die Schaffung von Plattformen, die es weniger technikaffinen Benutzern ermöglichen, benutzerdefinierte KI-Agenten für ihre spezifischen Bedürfnisse auf einfache Weise zu erstellen und anzuwenden.
Schließlich eröffnet der Bedarf an schneller Token-Generierung in RAG-Systemen Chancen in der KI-Infrastruktur und Modelloptimierung. Iterative Workflows leben von der schnellen Erzeugung möglichst vieler Tokens für interne Agenten. Unternehmen, die leistungsfähige und kostengünstige Infrastrukturen für den Betrieb von RAG-Systemen im großen Maßstab bereitstellen, stoßen auf eine große Nachfrage. Denn immer mehr Unternehmen möchten diese Technologien übernehmen.
Tipp:
Der Erfolg eines RAG-Systems steht und fällt mit der Qualität der zugrunde liegenden Datenquelle. Um Halluzinationen effektiv zu minimieren und präzise Antworten zu garantieren, sind sauber strukturierte und menschlich validierte Datensätze unerlässlich. clickworker unterstützt Sie dabei, die notwendige Ground-Truth-Datenbasis für Ihre Retrieval-Systeme aufzubauen.
Hochwertige KI-Trainingsdaten sichern
GraphRAG ist ein relativ neuer Ansatz für RAG. Hier werden Wissensgraphen verwendet, um vernetzte Informationen effektiver zu speichern und abzurufen. Wissensgraphen wurden bereits mit großem Erfolg eingesetzt – beispielsweise zur Unterstützung der Google-Suche.
GraphRAG bietet erhebliche Verbesserungen, aber auch Nachteile – insbesondere in Bezug auf die Rechenkosten und Komplexität. Die Erstellung und Pflege des Wissensgraphen, einschließlich Entitätsextraktion, Beziehungsidentifikation und mehrstufiger Zusammenfassung, kann erheblich teurer sein als traditionelle RAG-Ansätze. Daher erfordert die Implementierung von GraphRAG eine sorgfältige Abwägung der Vorteile zwischen verbesserter Leistung und erhöhten Rechenkosten.
In einer kürzlichen Vorlesung im Kurs Stanford CS25: Transformers United V3 teilte Douwe Kiela von Contextual AI wertvolle Einblicke in den aktuellen Stand und die Zukunft von Retrieval-Augmented Generation (RAG)-Systemen. Er hob mehrere Schlüsselbereiche hervor, in denen RAG erhebliche Fortschritte macht und in denen zukünftige Entwicklungen wahrscheinlich sind.
Kiela betonte die erheblichen Leistungsverbesserungen, die RAG-Systeme für Sprachmodelle bringen:
Kiela ging auf einige ethische Implikationen von RAG-Systemen ein:
Retrieval Augmented Generation (RAG) ist ein bedeutender Fortschritt in der KI-Technologie. Es kombiniert die Leistungsfähigkeit großer Sprachmodelle mit der Fähigkeit, auf externe Wissensquellen zuzugreifen und diese zu nutzen. Dieser hybride Ansatz gleicht viele Einschränkungen traditioneller KI-Systeme aus. Er bietet mehr Genauigkeit, reduziert Halluzinationen und verbessert die Fähigkeit, mit aktuellen Informationen zu arbeiten.
Wie wir gesehen haben, haben RAG-Systeme weitreichende Anwendungen in verschiedenen Geschäftssektoren: von der Verbesserung des Kundenservice bis hin zur Revolutionierung von Forschungs- und Entwicklungsprozessen. Die Fähigkeit dieser Technologie, kontextuell relevantere und faktisch fundierte Antworten zu liefern, eröffnet neue Möglichkeiten für KI-gesteuerte Lösungen im Wissensmanagement, personalisierten Marketing, rechtlicher Compliance und darüber hinaus.
Allerdings ist Retrieval Augmented Generation nicht ohne Herausforderungen. Aktuelle Systeme haben Probleme mit der Skalierbarkeit, dem Kontextverständnis und der Komplexität der Integration verschiedener Wissensquellen. Neue Lösungen wie GraphRAG zeigen allerdings das Potenzial, diese Einschränkungen zu überwinden. Sie nutzen Wissensgraphstrukturen, um das Kontextverständnis und die Beziehungskartierung zu verbessern.
In der Zukunft wird RAG-Technologie wahrscheinlich ein großer Teil des täglichen Lebens für Millionen von Menschen sein. Bis zur untersten Ebene verfügt dann jeder Mitarbeiter über einen persönlichen KI-Assistenten. Auf höherer Ebene werden Regierungen die Möglichkeit haben, fundiertere und effektivere Entscheidungen zu treffen, wenn sie auf effektive Weise eine ansonsten unüberschaubare Menge von Daten nutzen.
Für Unternehmen und Organisationen, die an der Spitze der KI-Technologie bleiben möchten, wird das Verständnis und die Nutzung von RAG-Systemen ein entscheidender Faktor für den Erfolg sein. Das Potenzial für gesteigerte Effizienz, verbesserte Entscheidungsfindung und optimierte Benutzererfahrungen macht RAG zu einem wichtigen Bereich, den es zu beobachten und in den es zu investieren gilt, wenn wir uns in Richtung eines Zeitalters der KI-gesteuerten Innovation bewegen.

